吉林大学计算机系统结构第三章《指令级并行》课堂笔记(曲冠南老师版)
第三章 指令级并行 (Instruction-Level Parallelism, ILP)
3.1 基本概念
指令级并行(ILP) 是指单个处理器中,通过硬件或软件技术,同时执行多条指令中不同操作的能力。其目标是提高指令吞吐率,减少程序执行时间。
核心思想:利用指令间的独立性,通过流水线(Pipelining)、乱序执行(Out-of-Order Execution, OoOE)、超标量(Superscalar) 等技术,让处理器在一个时钟周期内发射和执行多条指令。
关键限制:
- 数据相关(真相关):后续指令依赖于前面指令的结果。
- 名称相关:包括反相关和输出相关,可通过寄存器重命名解决。
- 控制相关:由分支指令引起的依赖。
3.2 指令流水线的深入与冒险
1. 流水线冒险 (Hazard)
- 结构冒险:硬件资源冲突。解决方法:资源重复(如哈佛架构分离指令/数据Cache,多端口寄存器文件)。
- 数据冒险:数据依赖导致无法获得正确操作数。
- 写后读 (RAW):真数据相关,必须等待。可通过旁路/转发 (Forwarding/Bypassing) 技术缓解。
- 读后写 (WAR) 与 写后写 (WAW):名称相关,可通过乱序执行与寄存器重命名消除。
- 控制冒险:分支指令改变PC,导致预取的下游指令无效。
2. 提高流水线性能
- 增加流水线级数(加深流水线):提高主频,但增加冒险惩罚和复杂度。
- 提高流水线吞吐率:每个周期发射多条指令(超标量、超长指令字VLIW)。
3.3 动态调度与乱序执行
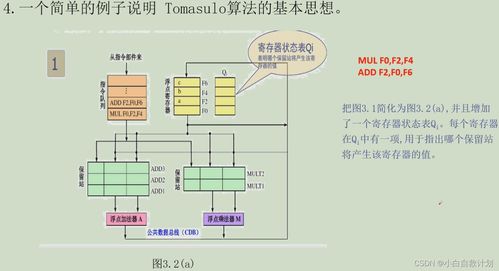
核心:记分牌算法 与 Tomasulo算法
Tomasulo算法(曲老师重点讲解)是动态调度、实现乱序执行的核心算法,尤其适合处理寄存器数量有限和长延迟操作(如访存、浮点运算)。
核心组件与流程:
1. 保留站 (Reservation Stations):缓存已发射但未执行的指令及其操作数(或指向操作数的标签)。
2. 公共数据总线 (CDB):用于将执行完毕的结果广播到所有需要该结果的保留站和寄存器文件。
3. 寄存器重命名:通过重排序缓冲 (ROB) 或保留站本身,将体系结构寄存器映射到物理寄存器或标签,彻底消除WAR和WAW冒险。
执行阶段:
- 发射 (Issue):指令顺序发射到空闲保留站,并监听操作数是否就绪。
- 执行 (Execute):当操作数全部就绪且功能单元空闲时开始执行(乱序)。
- 写回 (Write Result):通过CDB广播结果。
3.4 分支预测
控制冒险是限制ILP的主要瓶颈之一,现代处理器采用分支预测来推测执行。
1. 静态分支预测:编译器主导。
- 策略:预测永远不跳转、永远跳转、根据跳转方向预测等。
2. 动态分支预测:硬件在运行时根据历史信息进行预测。
- 分支历史表 (BHT):用分支指令地址的低位索引一个表,表中记录上一次该分支是否跳转(1位预测器)。
- 两位饱和计数器预测器:状态机(00-不跳转,11-跳转),只有连续两次预测错误才改变预测方向,抗干扰能力强。
- 相关(两级)分支预测:利用其他分支的历史结果来预测当前分支(如GShare, Tournament Predictor)。
- 分支目标缓冲 (BTB):缓存预测跳转的分支的目标地址,实现快速取指。
3.5 多发射处理器
1. 超标量 (Superscalar)
- 硬件在运行时动态检查指令间的依赖性,每个周期可发射可变数量的指令(如2-8条)。
- 代表:现代x86、ARM高性能核心。
- 关键挑战:依赖检查逻辑复杂,随着发射宽度增加,复杂度呈指数增长。
2. 超长指令字 (VLIW)
- 编译器在编译时静态分析指令间的并行性,将多条可并行执行的操作打包成一条很长的指令(一个“包”)。
- 硬件简单,但依赖于智能编译器,且二进制代码兼容性差。
- 代表:Intel Itanium (IA-64) 的EPIC架构。
3.6 性能限制与ILP的未来
限制ILP的因素:
- 真实的数据依赖(程序固有的)
- 过程(函数调用)和分支
- 指令发射、执行、提交的带宽限制
- 存储系统延迟(Cache Miss)
超越ILP的技术:当单线程ILP挖掘接近极限时,计算机体系结构转向:
- 线程级并行 (TLP):同时多线程 (SMT)、多核 (Chip Multiprocessor)。
- 数据级并行 (DLP):SIMD指令扩展(如SSE, AVX, Neon)。
- 请求级并行 (RLP):面向吞吐量计算,如GPU。
---
本章:指令级并行是现代高性能CPU设计的基石。从经典的5级流水线出发,通过动态调度(Tomasulo)、分支预测、多发射(超标量/VLIW)等一系列复杂技术,尽可能地挖掘程序中的指令间并行性。ILP的收益存在递减效应,这推动了多核与异构计算时代的到来。
如若转载,请注明出处:http://www.jidbbd.com/product/57.html
更新时间:2026-06-19 19:23:13